Podaci se svakodnevno skupljaju u ogromnom broju, a upravljanje velikim podacima najvažniji je slučaj upotrebe tražilice Elasticsearch. Podaci se pohranjuju u analitičku bazu podataka u stvarnom vremenu, a korisniku je dopušteno ekstrahirati podatke kako bi iz njih pronašao korisna znanja pomoću upita. Korisnik može primijeniti upite kako bi pronašao podatke iz više indeksa i prikazao ih u jednom segmentu iz relacijske baze podataka.
Ovaj će vodič objasniti Elasticsearch agregacije s primjerima koji koriste različite agregacije.
Što je Elasticsearch Aggregation?
U Elasticsearchu, agregacija je proces kombiniranja ili grupiranja polja za izvlačenje informacija iz relacijske baze podataka. Agregacija u Elasticsearchu može se smatrati GRUPI PO KLAUZULI ili AGREGATE() funkcija u SQL jeziku.
Kako koristiti Elasticsearch agregaciju?
Za korištenje agregacije u Elasticsearchu, korisnik mora imati osnovno razumijevanje svoje baze podataka. Istražimo sintaksu i njenu praktičnu primjenu:
Sintaksa
Za pronalaženje podataka iz baze podataka, sintaksa agregacije u tražilici Elasticsearch kao u nastavku:
'aggs' : {'naziv_agregacije' : {
'vrsta_agregacije' : {
'polje' : 'naziv_polja_dokumenta'
}
Gornji isječci:
-
- Koristi ' aggs ” ključna riječ koja objašnjava upotrebu agregacije u upitu.
- The naziv_agregacije postavlja korisnik prema traženim informacijama.
- Nakon toga, vrsta_agregacije koristi se za dobivanje podataka.
- Posljednji redak koristi polje ključnu riječ koju prati naziv atributa iz dokumenta.
Primjer 1: Agregacija u podacima uzorka Kibana
Ovaj odjeljak objašnjava agregaciju uz pomoć primjera koristeći ogledne podatke iz Kibane tako da se prvo povežete s njom. Nakon toga jednostavno uđite u ' Razvojni alati ” pretraživanjem iz trake za pretraživanje i klikom na njega:
Dohvaćanje podataka iz uzorka podataka
Jednostavno koristite sljedeću naredbu za dohvaćanje podataka iz ' kibana_uzorak_zapisi_podataka ” na konzoli Dev Tools:
DOBITI / kibana_uzorak_zapisi_podataka / _traži
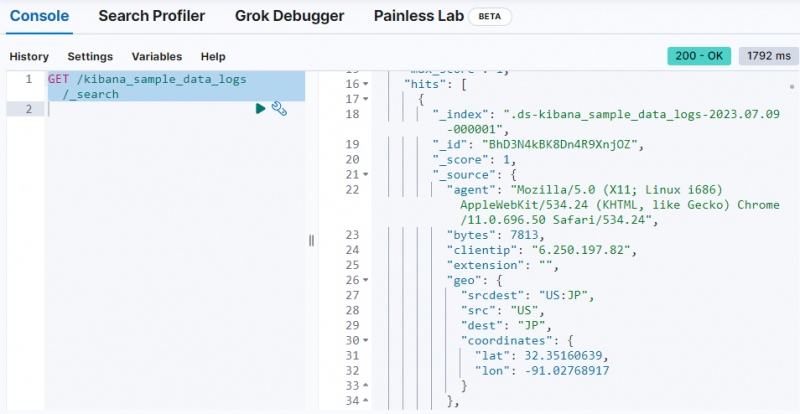
Izlaz pokazuje da su podaci dohvaćeni iz ' kibana_uzorak_zapisi_podataka ” indeks.
Sljedeći kod koristi a DOBITI zahtjev na ' dnevnik_podataka_uzorka kibana ' za pretraživanje iz njega pomoću agregacije value_count na ' clientip ” polje:
DOBITI / kibana_uzorak_zapisi_podataka / _traži{ 'veličina' : 0 ,
'aggs' : {
'ip_count' : {
'broj_vrijednosti' : {
'polje' : 'tip klijenta'
}
}
}
}
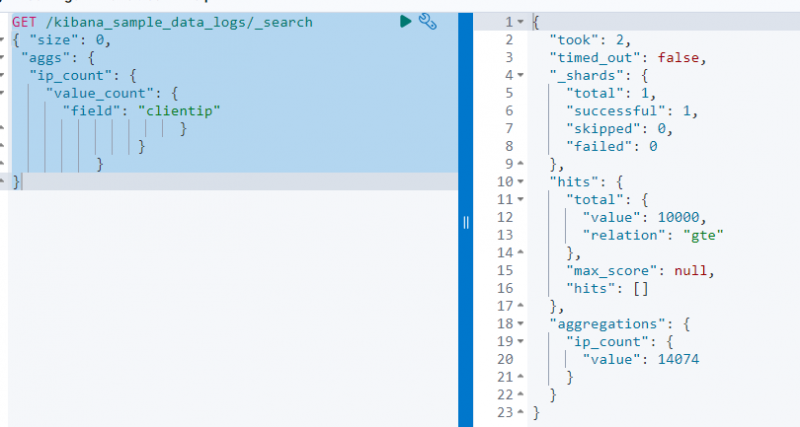
Gornji snimak zaslona prikazuje agregaciju na clientip polje s vrijednošću 14074 .
Važna združivanja
Neke od važnih jedinica združivanja koje se koriste za učinkovito pronalaženje podataka iz baze podataka navedene su u nastavku:
Sljedeći primjeri objašnjavaju gore spomenuta združivanja pomoću DOBITI zahtjev od “ kibana_sample_data_ecommerce ” indeks:
Agregacija kardinalnosti
Sljedeći kod koristi ' kardinalnost ' agregacija na ' sku ” iz podataka o e-trgovini. Pokretanje ovog koda dobit će agregaciju jedne vrijednosti za dobivanje jedinstvenih SKU-ova iz Elasticsearch baze podataka:
DOBITI / kibana_sample_data_ecommerce / _traži{
'veličina' : 0 ,
'aggs' : {
'unique_skus' : {
'kardinalnost' : {
'polje' : 'sku'
}
}
}
}
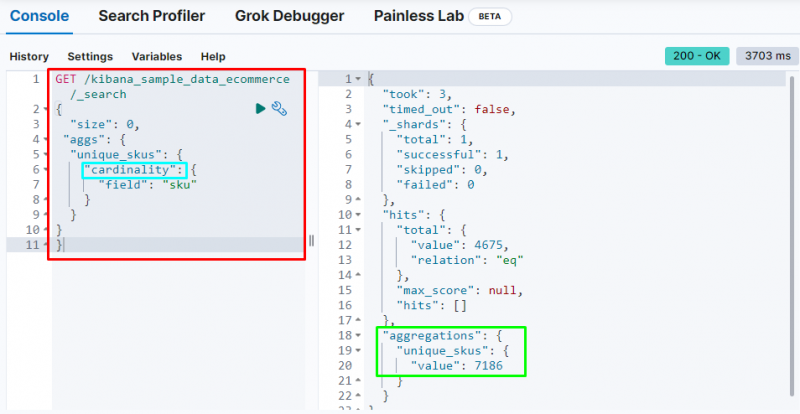
Prikazuje kardinalnost aggregation pronalaženje 7186 vrijednosti iz indeksa.
Agregacija statistike
Druga važna agregacija je ' statistika ' agregacija koja se koristi za dobivanje ' računati ”, “ min ”, “ max ”, “ prosj ', i ' iznos ” statistika iz “ ukupna količina ” polje:
DOBITI / kibana_sample_data_ecommerce / _traži{
'veličina' : 0 ,
'aggs' : {
'statistika_količine' : {
'statistika' : {
'polje' : 'ukupna količina'
}
}
}
}
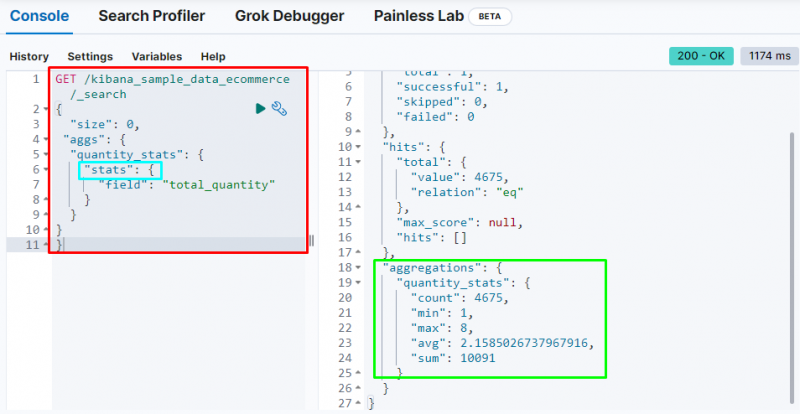
Gornja snimka zaslona prikazuje statistiku u izlazu iz ' ukupna količina ” polje.
Agregacija filtara
Agregacija filtara koristi se za filtriranje podataka na temelju izraza ili fraze iz baze podataka jer to sadrži sljedeći kod:
DOBITI / kibana_sample_data_ecommerce / _traži{ 'veličina' : 0 ,
'aggs' : {
'filter_agregacija' : {
'filtar' : {
'termin' : {
'korisnik' : 'eddie' } } ,
'aggs' : {
'prosj. cijena' : {
'prosjek' : {
'polje' : 'proizvodi.cijena' } }
} } } }
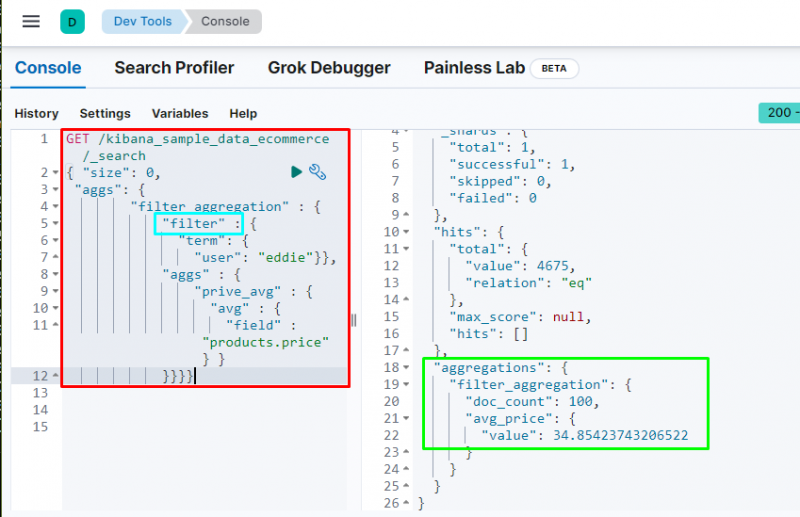
Izvršenje koda filtrirat će podatke na temelju ' eddie ” korisnika i prikazuje prosječnu cijenu kupljenih artikala. Gornja snimka zaslona prikazuje da je korisnik pronašao 100 puta iz podataka i vrijednost od prosj _ cijena agregacija.
Agregacija pojmova
Izraz agregacija stvara kantu i pohranjuje podatke iz polja u kantu, a sljedeći kod koristi ' korisnik ” za pohranu podataka u spremnik:
DOBITI / kibana_sample_data_ecommerce / _traži{
'veličina' : 0 ,
'aggs' : {
'Agregacija_pojmova' : {
'Pojmovi' : {
'polje' : 'korisnik'
}
}
}
}
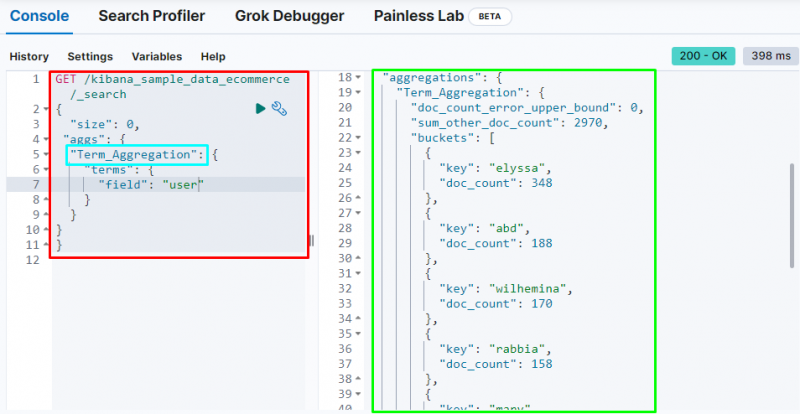
Sljedeća snimka zaslona prikazuje da je agregacija izraza stvorila segmente za svakog korisnika i njihov broj dokumenata.
To je sve o Elasticsearch agregaciji i različitim važnim agregacijama.
Zaključak
U Elasticsearchu, agregacija se koristi za dobivanje podataka iz agregiranih dokumenata, a ti se dokumenti izdvajaju iz određenog polja. Objašnjene su neke važne jedinice združivanja koje se koriste za dobivanje korisnih uvida iz indeksa. Ovaj vodič je objasnio Elasticsearch agregaciju i demonstrirao proces korištenja Elasticsearch agregacije.